Analysis of Random Forests in predicting the number of 6s hit in IPL

INTRODUCTION
Cricket, with its global popularity and complex gameplay, is very fertile ground for statistical analysis. The many quantitative elements offer unique opportunities for analytical observations. The use of statistical analysis in cricket has become crucial, whether it is informing team predictions, player selection, match outcomes, or even fan predictions (Cricket Webs, 2023). As the demand for deeper insights grows, traditional statistical methods are being aided by machine learning algorithms that can identify patterns and make data-driven predictions.
Despite their growing popularity in other areas, random forests, an ensemble learning approach (Breiman,2001), haven’t gotten as much attention in cricket analytics compared to other machine learning and artificial intelligence techniques. This means there's a lot of potential to be unlocked using Breiman's original algorithm and its variations to analyze cricket data, especially in shorter format games with multiple rounds and datasets.
The Indian Premier League (IPL) is a T20 cricket league that has gained massive popularity throughout the world. It displays some of the best cricket players worldwide and offers a wealth of statistical data that can be used for detailed analysis. The dataset that was used in this research is made up of carefully recorded performance and match outcomes in addition to all sorts of in-game statistics that have been gathered through 4 IPL seasons from the years 2018 to 2022.
This article examines different machine learning algorithms in cricket and explores the effect of different powerful algorithms within cricket data. While several algorithms offer valuable tools for such analysis, we will take a look at how random forests emerge as a very accurate predictor of the number of sixes hit by an individual.
RANDOM FORESTS
Random forests have emerged as a powerful ensemble learning technique within the field of machine learning. It is considered an ensemble learning algorithm because it combines the predictions from multiple machine learning algorithms to make more accurate predictions than any individual model. Specifically, a Random Forest builds many decision trees and merges them to get a more accurate and stable prediction.
Random forests build on the idea of bagging. This involves creating multiple classification and regression trees using random subsets of the training data (with replacement). This approach combats the instability of individual classification and regression trees, which can be overly sensitive to small changes in the data (Ziegler and König, 2011).
ANALYSIS OF DATA IN CRICKET
The Area Under the Curve (AUC) is among the key metrics of machine learning, regardless of the primary focus of the evaluation of the classification model. It is derived from the Receiver Operating Characteristic (ROC) curve, which is a graphical representation of a model's performance across various threshold settings. Accuracy, too, is a very familiar term in the context of machine learning, especially when working with classification problems. Accuracy is a fraction showing how many predictions are correct out of all the predictions being made.
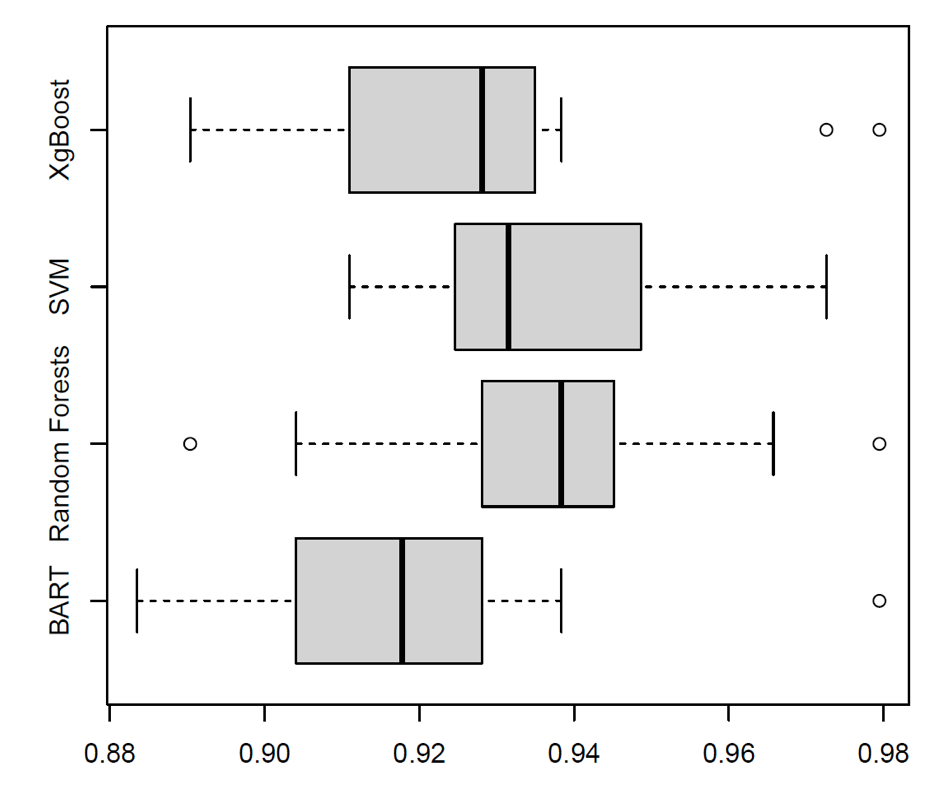
1 . Boxplot of Accuracy for 20 train/test splits for predicting if a player hit over five sixes in the season.
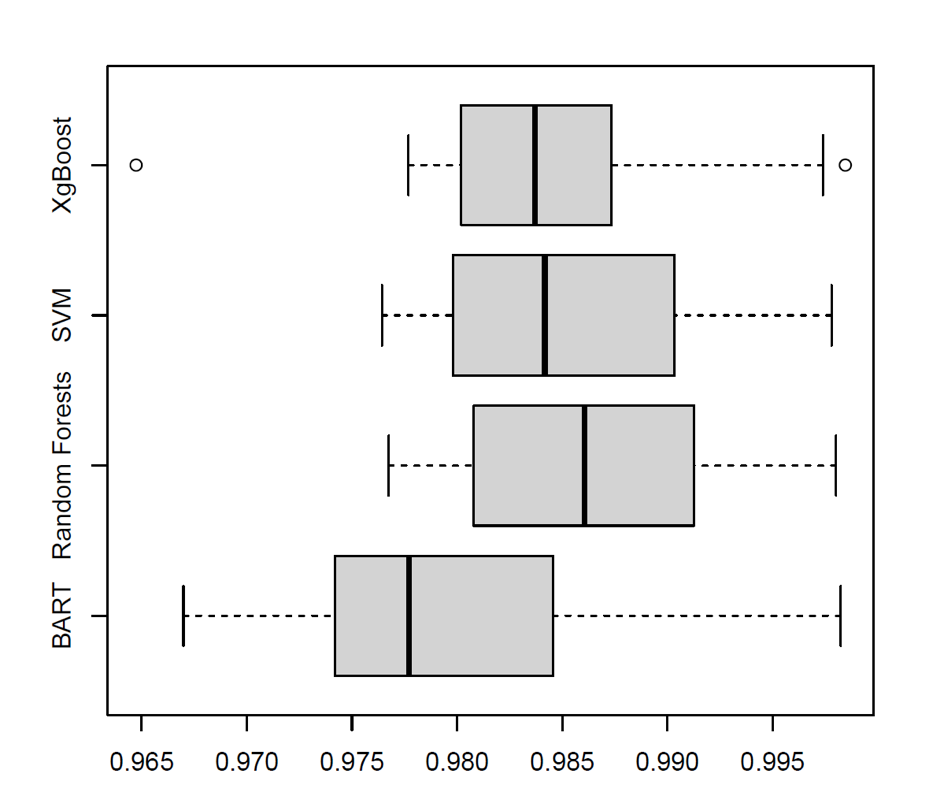
2. Boxplot of AUC values.
The dataset was pre-processed and split into training and test sets. The Random Forest, SVM, and XGBoost models were then trained on the training data, followed by predictions on the test data. . Accuracy was plotted to assess the correct classification of sixes, while AUC was used to evaluate the models' classification capability across varying decision thresholds.
Random Forests is shown to be superior compared to other models like Support Vector Machines (Cortes and Vapnik, 1995), BART (Chipman et al., 2010), and XGBoost (Chen and Guestrin, 2016). The boxplot has been used to compare accuracy and AUC (Area Under the Curve) scores. The accuracy boxplot in Figure 1 suggests that Random Forests are more powerful and have higher median accuracy values (0.92-0.98) than the rest in predicting a binary outcome of whether a player hits over five sixes in the season, making it a superior performance and stability model. In the same manner, the AUC boxplot in Figure 2 exhibits the ability of Random Forests to apply more accurate classifications, showing a more compact distribution with the AUC median values (0.97-0.99) than SVM and XGBoost. These results suggest that Random Forests are more effective in capturing the nuances of the dataset, likely due to their ensemble learning approach, which reduces overfitting and enhances predictive performance.
CONCLUSION
Preliminary findings indicate that RF is more effective in calculating if a player hit over five sixes in the season or not in comparison to other algorithms. Its capability to work with different kinds of data, like numerical and categorical data with IPL characteristics, makes it versatile for adding up different data. The inherent randomness in tree construction helps in avoiding overfitting, a common challenge in predictive modeling.
By aggregating the predictions of multiple trees, Random Forests achieve superior predictive accuracy. This ensemble approach reduces the impact of outliers in the data, leading to more reliable estimates of sixes. Having a reliable estimate of sixes not only enhances team strategies and player evaluations but also empowers coaches and broadcasters to efficiently make informed decisions from player retention to marketing campaigns.
REFERENCES
Breiman, L. (2001). Random Forests. Machine Learning, 45(1):5–32.
Chipman, H. A., George, E. I., and McCulloch, R. E. (2010). Bart: Bayesian additive regression trees. The Annals of Applied Statistics, 4(1):266–298.
Cortes, C. and Vapnik, V. (1995). Support-vector networks. Machine learning, 20(3):273–297
Chen, T. and Guestrin, C. (2016). Xgboost: A scalable tree-boosting system. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 785–794. ACM
Ziegler, A. and K¨onig, I. R. (2011). Mining data with random forests: current options for real-world applications. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 1(1):55–63
Cricket Webs. (2023). Cricket Technology: How Data and Analytics Are Shaping the Sport.